Ziyi Wu1,2,3,
Aliaksandr Siarohin1,
Willi Menapace1,
Ivan Skorokhodov1,
Yuwei Fang1,
Varnith Chordia1,
Igor Gilitschenski2,3,*,
Sergey Tulyakov1,*
1Snap Research
2University of Toronto
3Vector Institute
* Equal Supervision
MinT is the first text-to-video model capable of generating sequential events and controlling their timestamps.
Real-world videos consist of sequences of events. Generating such sequences with precise temporal control is infeasible with existing video generators that rely on a single paragraph of text as input. When tasked with generating multiple events described using a single prompt, such methods often ignore some of the events or fail to arrange them in the correct order. To address this limitation, we present MinT, a multi-event video generator with temporal control. Our key insight is to bind each event to a specific period in the generated video, which allows the model to focus on one event at a time. To enable time-aware interactions between event captions and video tokens, we design a time-based positional encoding method, dubbed ReRoPE. This encoding helps to guide the cross-attention operation. By fine-tuning a pre-trained video diffusion transformer on temporally grounded data, our approach produces coherent videos with smoothly connected events. For the first time in the literature, our model offers control over the timing of events in generated videos. Extensive experiments demonstrate that MinT outperforms existing commercial and open-source models by a large margin.
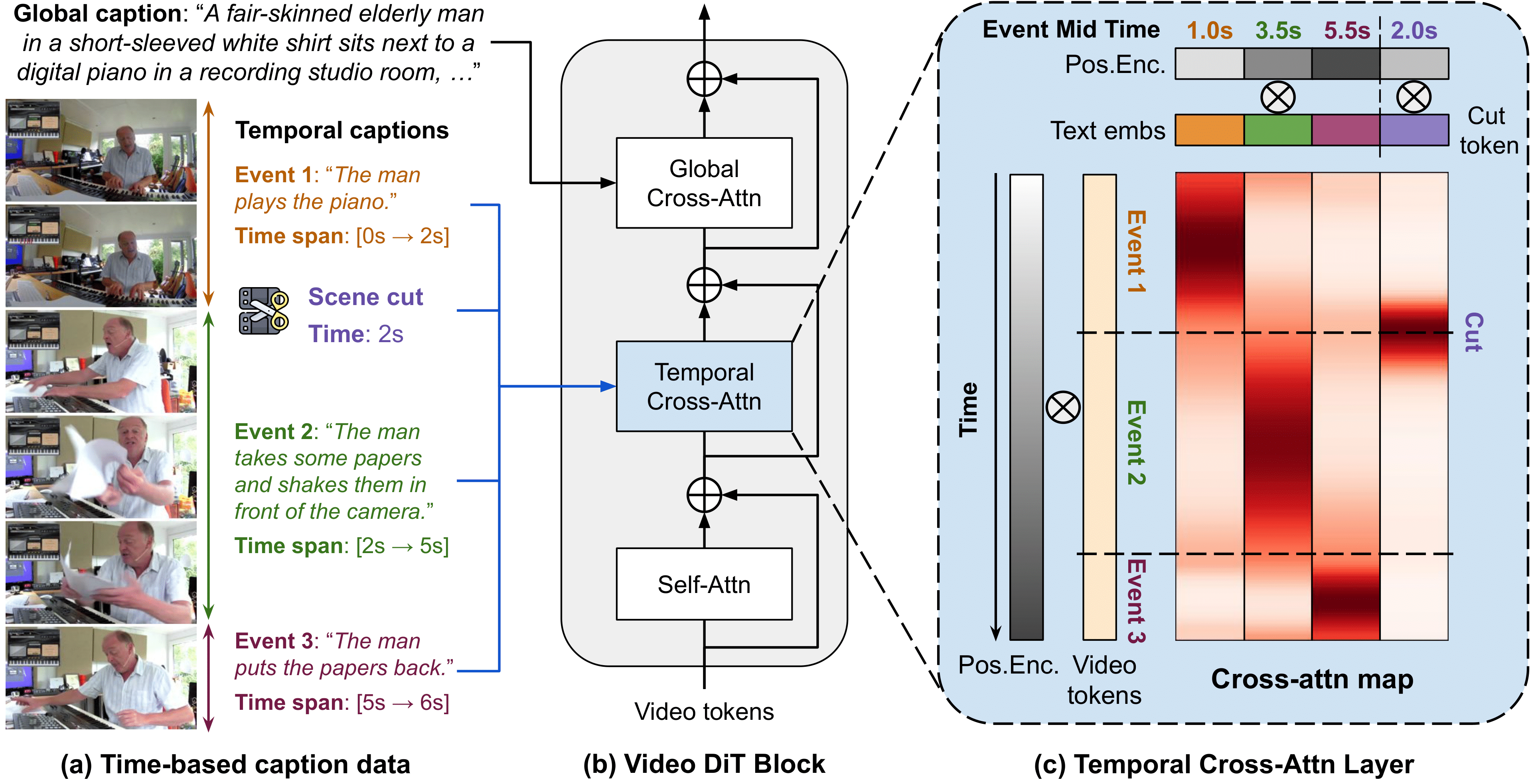
(a) Our model takes in a global caption, a list of temporal captions, and scene cut conditioning (optional).
Each temporal caption and scene cut is binded to a time span in the video.
(b) To condition on time-based event captions, we introduce a new temporal cross-attention layer in the DiT block.
(c) We design a novel Rescaled Rotary Position Embedding (ReRoPE) to indicate temporal correspondence between video tokens and event captions & scene cut tokens (optional).
This allows MinT to control the start and end time of events and the shot transition time.
Here, we show some high-resolution videos (1024x576). We use colored borders and subtitles to indicate the time period of each event. We first play the video with a pause before each event, and then play it continuously again. You can find more 512x288 videos (the resolution we used for the main experiments) here.
Sora [9] has a storyboard function (released one week after MinT) that supports multiple text prompts + time control. We run Sora with the same event captions and timestamps as our model and compare the results below. Despite being designed for this task, Sora still sometimes misses events, introduces undesired scene cuts, and is inaccurate on the event timing.
| Temporal Captions | MinT (Ours) | Sora (Storyboard) | |||
|---|---|---|---|---|---|
|
[0.0s → 2.3s]: A man lifts up his head and raises up both arms. [2.3s → 4.5s]: The man lowers down his head and puts down both arms. [4.5s → 6.8s]: The man turns his head to the right and extends both arms to the right. [6.8s → 9.1s]: The man turns his head to the left and extends both arms to the left. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 2.3s]: A young man typing on the laptop keyboard with both hands. [2.3s → 4.5s]: The man touches the headphones with his right hand. [4.5s → 6.5s]: The man closes the laptop with his left hand. [6.5s → 9.1s]: The man stands up. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 1.8s]: The woman is holding the phone in her left hand, looking at it while tapping on it with her right hand. [1.8s → 3.8s]: The woman holds the phone with both hands, extending them forward at face level to take a selfie. [3.8s → 7.0s]: The woman lowers the phone and begins typing on it with her right hand. [7.0s → 12.2s]: The woman adjusts her hair with her right hand, tucking it behind her left ear. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 1.2s]: The man holds an tablet with his left hand and uses it with his right hand. [1.2s → 5.6s]: The man looks at the blue bottles on his left and points his right hand towards them. [5.6s → 6.5s]: The man looks at the tablet and uses it with his right hand. [6.5s → 12.2s]: The man looks at the camera while holding the tablet with his left hand. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 2.1s]: The woman waves with her right hand. [2.1s → 7.5s]: The woman talks gesturing with her hands. [7.5s → 10.5s]: The woman makes a heart gesture. [10.5s → 12.2s]: The woman gives a blow kiss with her right hand. Playback Speed: |
|||||
|
|
|||||
Existing video generators struggle with sequential event generation.
We compare with SOTA open-source models CogVideoX-5B [1] and Mochi 1 [2], and commercial models Kling 1.5 [3] and Gen3-Alpha [4].
We concatenate all temporal captions to one long prompt, and run their online APIs to generate videos.
The prompt we used for SOTA models can be found at prompts.
Existing models often miss some events in the result, or merge multiple events and confuse their orders.
In contrast, MinT synthesizes all events seamlessly following their desired time spans.
Please refer to paper Appendix C.6 for more analysis on SOTA model behaviors.
Check out more comparisons here.
| Temporal Captions | MinT (Ours) | CogVideoX-5B | Mochi 1 | Kling 1.5 | Gen-3 Alpha |
|---|---|---|---|---|---|
|
[0.0s → 2.3s]: A man lifts up his head and raises up both arms. [2.3s → 4.5s]: The man lowers down his head and puts down both arms. [4.5s → 6.8s]: The man turns his head to the right and extends both arms to the right. [6.8s → 9.1s]: The man turns his head to the left and extends both arms to the left. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 2.3s]: A young man typing on the laptop keyboard with both hands. [2.3s → 4.5s]: The man touches the headphones with his right hand. [4.5s → 6.5s]: The man closes the laptop with his left hand. [6.5s → 9.1s]: The man stands up. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 1.8s]: The woman is holding the phone in her left hand, looking at it while tapping on it with her right hand. [1.8s → 3.8s]: The woman holds the phone with both hands, extending them forward at face level to take a selfie. [3.8s → 7.0s]: The woman lowers the phone and begins typing on it with her right hand. [7.0s → 12.2s]: The woman adjusts her hair with her right hand, tucking it behind her left ear. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 1.2s]: The man holds an tablet with his left hand and uses it with his right hand. [1.2s → 5.6s]: The man looks at the blue bottles on his left and points his right hand towards them. [5.6s → 6.5s]: The man looks at the tablet and uses it with his right hand. [6.5s → 12.2s]: The man looks at the camera while holding the tablet with his left hand. Playback Speed: |
|||||
|
|
|||||
|
[0.0s → 2.1s]: The woman waves with her right hand. [2.1s → 7.5s]: The woman talks gesturing with her hands. [7.5s → 10.5s]: The woman makes a heart gesture. [10.5s → 12.2s]: The woman gives a blow kiss with her right hand. Playback Speed: |
|||||
|
|
|||||
MinT is fine-tuned on temporal caption videos that mostly describe human-centric events. Yet, we show that our model still possesses the base model's ability to generate novel concepts. Here, we show videos generated by MinT conditioned on out-of-distribution prompts. Check out more OOD results here.
| Temporal Captions | MinT (Ours) |
|
[0.0s → 2.4s]: A sweeping crane shot reveals two warriors on the edge of the rugged cliffs, swords at the ready. [2.4s → 4.3s]: One warrior advances, swinging his sword in a wide arc aimed at his opponent's side. [4.3s → 6.7s]: The other warrior parries the attack, causing a shower of sparks to fly from the swords' contact. [6.7s → 9.1s]: The camera cranes up to capture both warriors circling each other, blades poised. |
|
|
[0.0s → 2.3s]: The astronaut bends forward to pick up a sparker from a metal container on the table. [2.3s → 4.5s]: The astronaut lights up a sparkler with a matchstick. [4.5s → 6.8s]: The astronaut waves the lit sparkler in a circle, leaving a trail of glowing sparkles. [6.8s → 9.1s]: The astronaut holds up the sparkler at eye level and admires the burst of colorful sparks. |
|
We leverage LLMs to extend a short prompt to a detailed global caption and temporal captions, from which we can generate more interesting videos with richer motion. The instruction we used for the LLM can be found at prompt. Here we compare with videos generated by our base model, using the original short prompt (dubbed Short), and the detailed global caption (dubbed Global). This allows regular users to use our model without the tedious process of specifying events and timestamps. Please refer to paper Appendix C.2 for more details.
| Captions | MinT (Ours) | Short | Global | ||
|---|---|---|---|---|---|
|
Short caption: a cat drinking water. Extended temporal captions: [0.0s → 1.7s]: A fluffy, orange cat walks towards a ceramic water bowl. [1.7s → 4.3s]: The cat has its pink nose dipping into the water as it begins to lap at the water with its tiny tongue. [4.3s → 8.1s]: The cat lifts its head and glances around the room with its green eyes. Playback Speed: |
|||||
|
|
|||||
|
Short caption: a bicycle accelerating to gain speed. Extended temporal captions: [0.0s → 2.2s]: The camera is at ground level capturing a close-up of the bicycle's wheels, standing still. [2.2s → 4.0s]: The camera tilts up to show the rider lightly pushing down on the pedal with their foot. [4.0s → 5.9s]: The camera zooms out to a medium shot, revealing the rider steadily pedaling while leaning forward. [5.9s → 8.1s]: A smooth track motion shows the bicycle racing down a street, gaining speed quickly. Playback Speed: |
|||||
|
|
|||||
|
Short caption: a bear catching a salmon in its powerful jaws. Extended temporal captions: [0.0s → 2.5s]: A large brown bear standing waist-deep in a rushing river. [2.5s → 4.3s]: The bear lunging catches a fish from the water. [4.3s → 8.1s]: The bear clenches a silver salmon in its jaws and lifts its head triumphantly. Playback Speed: |
|||||
|
|
|||||
|
Short caption: a bear climbing a tree. Extended temporal captions: [0.0s → 1.3s]: A brown bear walks towards a tall tree. [1.3s → 3.3s]: The bear stands on its hind legs and places its front paws on the tree trunk. [3.3s → 6.0s]: The bear slowly climbs higher up the tree. [6.0s → 8.1s]: The bear pauses to catch its breath. Playback Speed: |
|||||
Long videos often contain rich events, yet they also come with many scene cuts.
Directly training a video generator on them will lead to undesired abrupt shot transitions in the generation result.
Instead, we propose to explicitly condition the model on scene cut timestamps during training.
Once the model learns such conditioning, we can set them to zeros to generate a cut-free video at inference time.
Here, we compare videos generated with different scene cut conditionings.
We pause the video at input scene cut time (highlighted with cyan borders).
Our model introduces desired shot transitions and can still preserve the subject identities and scene backgrounds.
Please refer to paper Appendix C.3 for more analysis.
| Temporal Captions | No Cut | Temporal Captions | After First Event | Temporal Captions | After All Events |
|---|---|---|---|---|---|
|
[0.0s → 3.5s]: Event1 [3.5s → 6.0s]: Event2 [6.0s → 9.1s]: Event3 |
[0.0s → 3.5s]: Event1 3.5s: Scene cut [3.5s → 6.0s]: Event2 [6.0s → 9.1s]: Event3 |
[0.0s → 3.5s]: Event1 3.5s: Scene cut [3.5s → 6.0s]: Event2 6.0s: Scene cut [6.0s → 9.1s]: Event3 |
|||
| Playback Speed: | |||||
|
|
|||||
|
[0.0s → 2.7s]: Event1 [2.7s → 6.6s]: Event2 [6.6s → 9.3s]: Event3 |
[0.0s → 2.7s]: Event1 2.7s: Scene cut [2.7s → 6.6s]: Event2 [6.6s → 9.3s]: Event3 |
[0.0s → 2.7s]: Event1 2.7s: Scene cut [2.7s → 6.6s]: Event2 6.6s: Scene cut [6.6s → 9.3s]: Event3 |
|||
| Playback Speed: | |||||
|
|
|||||
|
[0.0s → 1.9s]: Event1 [1.9s → 4.0s]: Event2 [4.0s → 6.2s]: Event3 [6.2s → 9.1s]: Event4 |
[0.0s → 1.9s]: Event1 1.9s: Scene cut [1.9s → 4.0s]: Event2 [4.0s → 6.2s]: Event3 [6.2s → 9.1s]: Event4 |
[0.0s → 1.9s]: Event1 1.9s: Scene cut [1.9s → 4.0s]: Event2 4.0s: Scene cut [4.0s → 6.2s]: Event3 6.2s: Scene cut [6.2s → 9.1s]: Event4 |
|||
| Playback Speed: | |||||
We show MinT's fine-grained control of event timings. In each example, we offset the start and end time of all events by a specific value. Each row thus shows a smooth progress of events happening. Please refer to paper Appendix C.4 for more details.
| -1.0s | -0.5s | Original Timestamps | +0.5s | +1.0s | |
|---|---|---|---|---|---|
| Playback Speed: | |||||
|
|
|||||
| Playback Speed: | |||||
|
|
|||||
| Playback Speed: | |||||
Here, we show several representative failure cases of our model.
1. Since we fine-tune from a pre-trained video diffusion model, we inherit all its limitations.
The following two examples show that MinT fails to handle human hands and complex physics well.
|
[0.0s → 2.5s]: The person on the left strokes the woman's hand. [2.5s → 6.0s]: The person holds the woman's hand firmly. The camera tilts up. [6.0s → 9.1s]: The woman responds to the person. The camera tilts up and dollies backward. |
|
|
[0.0s → 3.3s]: A light-skinned person cuts a strawberry with a knife. [3.3s → 5.9s]: The person cuts the strawberry into four pieces. [5.9s → 9.1s]: The person pushes the strawberry pieces towards the left with a knife. |
|
2. Another failure case is multi-subject scenes. The below example shows a video with multiple persons, where MinT fails to bind attributes and actions to the correct person. While we mainly focus on temporal binding in this paper, this issue might be solved with spatial binding, such as bounding box controlled video generation [8].
|
[0.0s → 3.4s]: The dark-skinned man says something, and the fair-skinned man holds a piece of pizza in his right hand and points his left hand to the tan-skinned man. The tan-skinned man is holding a piece of pizza in his left hand. [3.4s → 6.1s]: The fair-skinned man points at the TV with his left hand while the tan-skinned man eats the pizza, and the dark-skinned man looks at the TV. [6.1s → 9.1s]: The fair-skinned man picks up a green bottle of cold drink and drinks it while the tan-skinned man picks up a green bottle, and the dark-skinned man looks at the TV. |
|
3. MinT sometimes fails to link subjects between global and temporal captions.
In this example, a woman is described to "wear a gray-red device on her eyes" in the global caption.
However, when prompted to "adjust the gray-red device" in the second event, she lifts a new device instead of the one on her eye.
We tried some simple solutions such as running a cross-attention between text embeddings of global and temporal captions before inputting them to the DiT, hoping it can learn to associate subjects, but it did not help.
Yet, this "binding" problem may simply be solved with more training data, which we leave for future work.
|
Global caption: A woman is doing eye-checking test. She wears a gray-red device on her eyes and ... [0.0s → 2.8s]: A woman looks forward. [2.8s → 6.3s]: The woman moves his hands up, adjusts the gray-red device, and moves her hands down. [6.3s → 9.1s]: The woman looks forward and nods her head. |
@inproceedings{wu2025mint,
title={Mind the Time: Temporally-Controlled Multi-Event Video Generation},
author={Wu, Ziyi and Siarohin, Aliaksandr and Menapace, Willi and Skorokhodov, Ivan and Fang, Yuwei and Chordia, Varnith and Gilitschenski, Igor and Tulyakov, Sergey},
booktitle={CVPR},
year={2025}
}
[1] CogVideoX-5B. https://huggingface.co/spaces/THUDM/CogVideoX-5B-Space.
[2] Mochi 1. https://www.genmo.ai/play.
[3] Kling 1.5. https://klingai.com/.
[4] Gen-3 Alpha. https://runwayml.com/research/introducing-gen-3-alpha.
[5] Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." ICCV. 2023.
[6] Su, Jianlin, et al. "RoFormer: Enhanced transformer with rotary position embedding." Neurocomputing. 2024.
[7] Huang, Ziqi, et al. "VBench: Comprehensive benchmark suite for video generative models." CVPR. 2024.
[8] Lian, Long, et al. "LLM-Grounded video diffusion models." ICLR. 2024.
[9] Sora. https://sora.com/.